The color of the shadows is very important in the whole scene of the game. Artists have direct control over the color of shadows throughout the scene, or the color and intensity of shadows on characters.
Shadow Stylized Color

The color of the shadows is very important in the whole scene of the game. Artists have direct control over the color of shadows throughout the scene, or the color and intensity of shadows on characters.

https://github.com/leegoonz/MaterialX_batchInstall MaterialX Shader generation

Clear-Coat compare
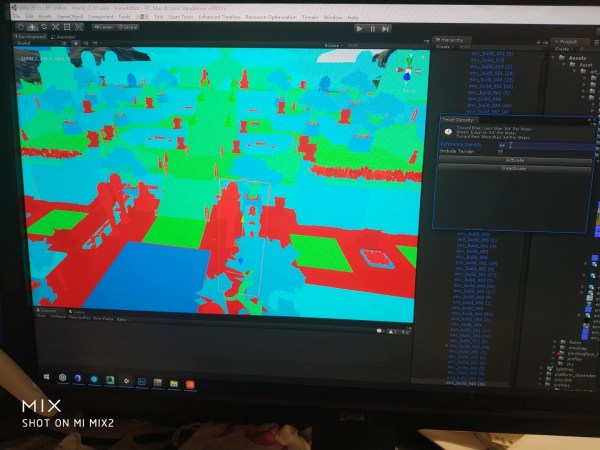
Texel density complexity viewer.






