Authored by JP。LEE
leegoonz@163.com
TECHNICAL ART DIRECTOR OF THE GIANT INTERACTIVE
07/12/2018
Purpose of this lecture
给90后新人美术简单介绍电脑图形历史,让他们认识到过去和现在,从而培养可以预估未来的洞察力。
这次分享的内容包含对 GPU 的介绍,对近期有变化的游戏图形优化因素的基本原理的介绍,使美术可以根据这些信息主动树立优化思路。
HISTORY OF MODERN GPU 1999
GPU(图形处理器) ARCHITECTURE的变迁
1999年发布了 NVIDIA 的 Ge-force 256 显卡。 这是第3代 gforce
HARDWARE T&L(transform & lighting),行列演算和向量内积, 乘法的累积演算 (Multiply accumulate operation)用 ‘fixed function hardware’ 实现。
! 3D PC 游戏的坐标变换开始在 GPU上执行。!
DIRECT X 7
但是很遗憾,这个时代比起 3D 游戏, 2D 游戏的开发才是主流。

HISTORY OF MODERN GPU 2000
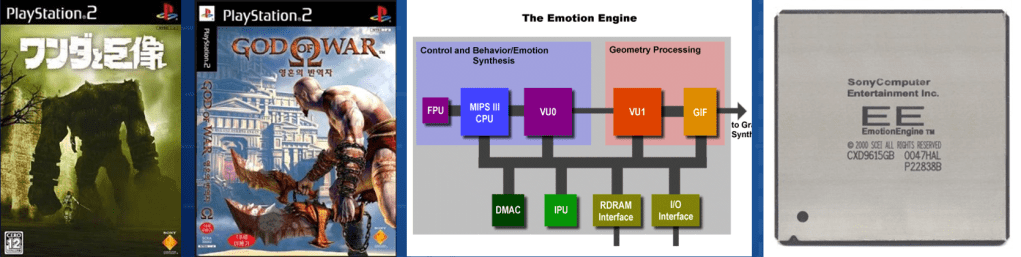
CPU的 Emotion Engine 的向量演算在单位上做几何处理。
这是基于 MIPS-III R5900 开发的,由 CPU 核, FPU, 向量处理单元 2个(VPU0, VPU1), 图形界面 (GIF), 10 通道 DMA, 内存控制器, 图形处理单位 (IPU), I/O 界面组成,各个单位连接到 128 Bit 内部数据总线。

2000年微软发布了用于Windows的图形 API DirectX 8 。
DirectX 8 不是固定功能,是可以定制玩家制作的微软管线的硬件, 是以Programmable shader 结构的 GPU为前提制作的。
2001年发布了支持 DiectX 8的 OS 微软Windows XP 和 GPU 的 Nvidia GPU 的 Geforce 3。
同一年开售的微软主机游戏机 ‘XBOX’ 内含定制 Geforce 3,支持,Programmable shader 。

HISTORY OF MODERN GPU 2001 ~ 2003
4代 GeForce 登场。
GeForce 3 和 GeForce 4 发行。
这是改造 3代 GPU ARCHITECTURE 的模型,所以有着只支持 DIRECTX 7.0 的缺点,是过度用的 GPU。
5代 GeForce 登场。
GeForce FX 发行。
支持 DirectX 9.0a 和 OpenGL 2.1 ,天堂 2 或 孤岛惊魂FARCRY1 或 毁灭战士DOOM3 可以跑起来了。
HISTORY OF MODERN GPU 2004 ~ 2008
2004年 8月开始 5代~6代 GeForce 登场。
发布了 GeForce FX 和 GeForce 6 ~7 。
GeForce 6 是完整支持 DirectX 9.0c的第一个系列。
开始支持 DirectX 9.0c 后,游戏的品质急剧上升。



2005年发布了 XBOX 360 / ATI GPU 的 Xenos 是用的 Unified shader 。
Unified shader 是同一个硬件的 Shader process 里处理 vertex shader 和 Pixel shader 两面,根据处理阶段和 game title 的特性,换成符合各个处理负荷的资源分配 ,做 Shader process 的负荷平衡。
2006年发布 PS3 。
用的是 NVIDIA 的 Reality Synthesizer GPU 。

HISTORY OF MODERN GPU 2008 ~ 2017
GeForce 7 代到 12 代。Core 芯片集开始全面发展起来。NVIDIA 以 Kepler Architecture 为开端,步入了高性能手机 GPU 领域。
NINTENDO SWITCH 的 GPU 是 MAXELL CORE 的 NVIDIA TEGRA X1 (T210) 。
以游戏为主运营体系的任天堂SWITCH 在游戏的驱动上可以期待比 A9X 或 A10 Fusion 更好的性能,实际性能比期待还高。 用多平台游戏堡垒之夜做了性能对比后发现超过了 iPhone X 的 A11 Bionic。

HISTORY OF MODERN GPU 2018
HDR 和 4K ,在图形处理有绝对优势的 PLAY-TATION 4 PRO。
影视视觉效果为主流的PC和主机游戏图形模范出现了。
这个时代对光源的精细处理和大气扩散效果, 3D空间的深度和高度的处理的要求很多。

NVIDIA 8th generation TURING GPU
加速Ray tracing (光线追踪) 的新 RT CORE(Ray-tracing core)。
在每秒最大 10Giga Ray 的 3D环境里,可以更快计算光和声音移动的方式。
支持 Real-time ray tracing的 AI(人工智能) 推理使用的 Tensor Core 每秒最多演算 500兆次 Tensor 。
HYBRID RENDERING
在复杂的模型上通过神经网和流体的相互作用实现影视水准的交互。


MOBILE GRAPHICS PARADIGM
GRAPHICS PROGRAM PARADIGM SHIFT [旧时代]
2009年 11月 28日 发布了可以跑 3D 游戏的 IPHONE 3GS 。
主导手游图像革新的 Epic games 的 Infinity Blade(无尽之剑)
发布后,全世界多数游戏开发公司都开始发布精致的 3D 游戏了。

2011年 Infinity blade(无尽之剑) 的下一个作品 Infinity blade 2 上线了。
IPhone 4S 的 Flag ship game 也可以跑起来了 。

2016年到 2018年现在为止,大部分是过渡期。
天堂2 revolution 和 剑灵 revolution 等游戏开始在整个场景投入实时照明效果。

FIRST NEW GENERATION
GRAPHICS PROGRAM PARADIGM SHIFT [新时代]
2014年在 GOOGLE I/O 发布的 EPIC GAMES.
NVIDIA SHIELD DEMO ( 和 NINTENDO SWITCH 相似的性能 )

2018年唯一一个决定只支持 OpenGL-es 3.1 以上的游戏。

2018年第一个支持 VULKAN 的手游上线了。 BLADE 2

NEXT GENERATION MOBILE HARDWARE
SPECIFICATION
GRAPHICS PROGRAM PARADIGM SHIFT
硬件上先出的合并Shader, Driver 和 API是之后完成的,这形成了一个新时代。

列表可以看出,不一样的特点是 GPU可以直接更新缓冲。
现在所有图形相关负荷最大的瓶颈就是 CPU > GPU 的指令。
这些指令可以分为三个种类。

我们看下…
Draw Call : 中国有时会叫做 DP(DrawPoint??) 之前就在沟通时弄混过。
– CPU要求 GPU 画出某种物体。
Batches
– 很多人跟 Draw call 混用,但其实这是包含Draw call 的更广泛的概念
– Draw Call + Set VB/IB + Set Transform + Set Pass Call (Set Shader + Set Texture 0~7 + Set Blending + Set Z enable。。)
Set Pass Call
– 指 Material 和 Shader 相关的 Batch。
不单独进行Batching时, Set Pass Call和 Material的关系
案例1 : 共享 Material的物体有 10个
– Batch是 10个, Set Pass Call用 1个, Batch总共是 11个。
案例2 : Material或 Shader不同的物体是 10个
– Batch是 10个, Set Pass Call是 10个, Batch总共是 20个。
Batching : 不要跟Batche弄混了。
– 是把多个Draw call 捆成一个Draw call 处理的工作

所有指令都有庞大的内存/演算 负荷。最终图形优化的核心就是从 cpu到 gpu不做指令,或合起来一次性做好减少次数。
这种优化方法里,有执行同一个程序(Shader)时为了不反复修改程序,根据材质整理好合起来 ( SRP Batcher, 只支持SRP, 2019.1开始 ) 的方法。
为了不进行多次 Draw,同一个材质的顶点和索引收集起来一起画
( Dynamic/Static Batch ), 在同样的状态下只修改参数的话一次性收集数据传过去减少负荷的方法。( GPU Instancing) 到这里为止是旧时优化方法。
在现代用更简单的方法解决这个问题。 方法 : 因为 GPU可以进行以 CPU 为准的计算了,所以要在 GPU更新。 这样就可以利用演算力强大的 GPU,不仅演算速度变快,持续从 cpu更新到 GPU的缓冲和参数的过程也会变少或变得不需要,可以大量减少 call 开销。
其中一个就是 Indirect Draw。
看成 Instancing Draw 的高效率版本就可以了。
Instancing Draw API 指令基本上是在 CPU 更新数据,只是把 Draw 指令合并起来了,相比之下 indirect draw 是画在 GPU 缓冲时需要的数据,所以是把这个作为参考做 Draw 的指令。
用 compute Shader 做 curling 做更新和 indirect draw, 用几个 Dis-patch 指令和一个 Draw 指令就能画出数百万个物体。
( 当然只能在新一代 API里才有的指令。)
https://www。khronos。org/registry/OpenGL-Refpages/es3。1/html/glDrawArraysIndirect。xhtml
用相同模式做出来的就是 VFX-Graph ( 现在是Beta, SRP专用, 预计2019年末上线? ) 。
更新的程序用 compute Shader做出来,在 GPU完成更新和画。
基本上所有 演算都放到 GPU里做,Shader的 80%是 Compute Shader 的 SRP HD。资源商城陆续出现了利用这个模式做成的插件。

UNDERSTANDING HARDWARE LIMITATIONS
手机硬件的变化和 bandwidth(带宽)。
Reference by SIGGRAPH 2015 Xroads of Discovery。

我们已经了解了GPU的模式,还有个重要的点。
现代的 GPU已经成长为比 Play-station 3 还高的性能。但为什么还是很难做出跟 Play-station 3 一样的图形处理,我们有必要想一下。这里的差距就是内存的带宽。在手机环境有很多要求是跟desktop一样的,但是内存带宽或电池,发热是不一样的。如果带宽有瓶颈,最终会让渲染速度变慢,电池的消耗也会上升。
我们祈祷 HBM 技术可以适用到手机环境里吧。

手游内存芯片的带宽已经接近 PC 主内存的带宽了。但是手机用的总线宽度通常是比 PC的 128 bit 小的 64 bit。
手机上是没有高性能 PC 图形系统为了渲染保持整体帧缓冲器的 ‘VRAM’ 缓冲器。

而且电池的消耗也是一个很大的拖后腿因素。
DDR 带宽消耗在游戏运行的电池使用量里占很大分量。
想提高手机图形的关键是减少 DDR 带宽消耗。

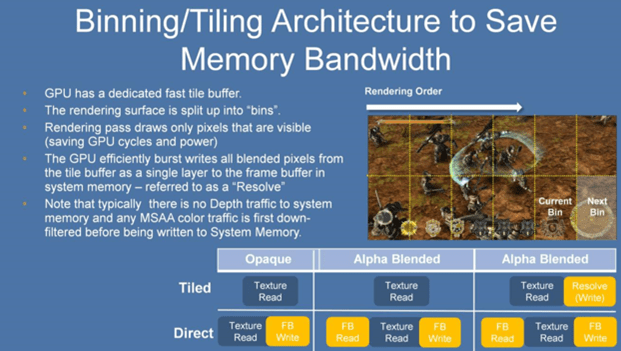
GPU里有一个叫 GMEM 的专用高速内存缓冲器。 渲染表面用 “Bin (bins)”分开。 Bin的大小是形式 (包含Z) 和渲染对象的分辨率用总 GMEM 除去的值来决定的。 储存器的数量根据硬件版本,对象分辨率的大小和对象显示的形式都不同。
每一个 Bin 生成三角形 “可视流”。Rendering Pass 会利用可视流把该 Bin 上可看的像素拿过来 (GPU 周期和电池的节约)。
各个 Bin 的所有像素都画出来了, 和 GPU功能一致的很高带宽的 GMEM里 GPU有效率地进行 Bust ,所有混合的像素在 GMEM 用单一的 Layer用于系统内存的帧缓冲器 (叫 “解决”)。 避开解决方法是重点。

次时代游戏的节约内存带宽的方法有很多种。
通常会有贴图的压缩, OpenGL 3.1 AEP 的重要功能 Tessellation 技法也是其中一个。RTC 这个是用于 ‘under-the-covers’的压缩技法。 纯粹的带宽 (不是内存空间) 压缩。让显示器理解这个格式,带宽会储存在帧缓冲器的写和显示器里。


跟美术有直接关联的是贴图的压缩,这也是最重要的部分。随着游戏的图形提高,一个Shader里也会用好几张贴图。以前连 PC 游戏也是手绘风贴图为主,但是现在的手游图形不仅是 PBR ,视觉表现上也需要大量的贴图。

结果就是,比起 GPU 的发展速度,手机的内存带宽还没有跟上 PC 或主机游戏硬件的发展速度。所以在手机的硬件环境下,美术要完全掌握节约内存带宽的方法,亲自修改贴图的密度和压缩格式,执行即在视觉上追求稳定,也能减少内存的方案。压缩贴图必然会发生画质的下降。
所以美术要尽量利用 UV 空间,多想和多测试怎么制作图形数据。

MASSIVLY FITTING UNPACKED UV。
利用 HOUDINI 的 MULTI COVERAGE UVLAYOUT WORKS。
MASSIVLY FITTING UNPACKED UV。
概念上的 MULTI COVERAGE UVLAYOUT WORKS。
设计造型时,原画最好树立重复图案(Tiling) 结构。

MIP-MAP ARTIST DRIVEN CONTROL
手机里的所有 Shader map 都需要 Mip-map 吗? 我们有必要像这种问题。
Mip-map 的有或无容量上有 1.35 倍的差距。
关掉 Mip-map 可以节省百分之 35 内存。

美术要对所有贴图进行视觉判断,进行把控。
下图有相当于 5.2 倍的容量差距。
但在手机上显示的话基本没有差距。

原理上, MIP-MAP 是把原贴图进行 Scale Down ,预先生成的技术。
视觉上在小画面上,以游戏的标准镜头距离为准使用跟 MIP-MAP 等级类似的 Scale Down 阶段的尺寸也不会有很大问题。
但是 MIP-MAP 阶段的 Pixel sampling count 减少的好处是得不到了。
但是先稳定带宽跟 ‘Modern GPU’ 的 pixel sampling 高速处理能力一起想就可以找到共识。
conclusion
即将到来的 2019年为起点会成为 OPENGL-ES 3.1 AEP 的时代,都使用高性能硬件和高配渲染 API的情况下每个公司的项目图像品质还不一样或者性能上有差距的话,是因为在不了解 GPU 的情况下进行开发的结果。
通过这次的分享,我们美术要多思考,开发次时代手游时为了做出更高的品质,更快的渲染性能要检查什么部分,进行怎样的优化,最终要获得什么结果。
如果自己做出的数据有压缩成低画质或强制被最小化的话,那都是因为自己的无知引起的,不能怪谁。
并且程序员要尽量减少 CPU BOUND ,集中想方案怎样才能把独立的 GPU 利用到极致。

댓글 남기기